
Column vs Row: Why It’s Time to Rethink How You Pay for ETL
Most data teams don’t avoid switching ETL platforms because they are satisfied. Rather, they stay because moving to a new provider feels risky, time-consuming, or difficult to get approved. However, the real risk lies in standing still.
In data infrastructure, we have long understood that column vs row storage directly impacts both performance and efficiency. Nevertheless, this logic has not yet been fully applied to pricing models.
The column vs row distinction highlights how row-based ETL pricing penalises scale. It charges for every row, regardless of its value. That’s akin to buying a car and being charged per engine revolution. In contrast, performance-based pricing rewards efficiency by linking costs to actual infrastructure use, not arbitrary row counts.
The Hidden Flaw in Row-Based Pricing Models
Consider this common complaint from data leaders: “Our data bill keeps rising, and we can’t explain why.” As businesses grow and data volumes increase, ETL costs often escalate rapidly—without delivering proportionate value.
Column vs row thinking offers clarity here. Columnstore indexing, used in modern databases such as SQL Server, Oracle, and Snowflake, provides multiple advantages:
1. High Data Compression
Because columns often contain repeating values, they compress more effectively. This leads to a 5x–10x reduction in storage.
2. Faster Analytical Queries
Analytical workloads typically access specific columns. Columnar storage reads only what is needed, improving performance.
3. Efficient Batch Processing
Batch mode processes data in groups, lowering CPU usage and improving execution times.
4. Fewer Secondary Indexes
Columnstores reduce the need for traditional indexing, simplifying maintenance.
5. Suited for Data Warehousing
Columnar formats align well with large, read-heavy workloads and infrequent updates.
6. Better I/O Performance
Compression and columnar access reduce memory use and disk I/O.
7. Segment Elimination
Query engines can skip irrelevant segments, further accelerating performance.
This same logic should apply to ETL pricing. If platforms are evolving, pricing must evolve too.
Summary: When to Use Columnstore Indexes
| Ideal Use Cases | Avoid If… |
| Large data warehouses | Heavy transactional (OLTP) workloads |
| Read-heavy analytical queries | Frequent row-level updates/deletes |
| Aggregation-heavy reports | Low-latency insert/update requirements |
Similar technology leaps are occurring at every level – including ETL. So if platforms are becoming more efficient, why are you still paying by volume?
Most legacy ETL platforms still use volume-based pricing models that charge you for every row processed, regardless of whether that data is:
- Valuable or redundant
- Changed or unchanged
- Actually used or just passing through
This outdated approach creates three critical problems:
1. Growth Gets Penalised, Not Rewarded
When your business succeeds and data volumes increase, your ETL costs skyrocket—even if the actual compute resources remain stable. This creates a perverse incentive where success drives financial pressure.
As one Head of Data told us: “We’ve reached the point where we actively discourage new analytics use cases because of the ETL cost implications. That’s not how data should work.”
2. Budgeting Becomes Impossible
Finance teams expect predictable costs, but with pricing tied to data volume rather than actual usage, a single new data source or traffic spike can blow your budget.
When the CFO asks “Why did our ETL bill jump 40% this quarter?” the answer shouldn’t be “Because our business is doing well.”
3. Efficiency Goes Unrewarded
Row-based pricing provides zero incentive for vendors to help you optimise. In fact, they make more money when your pipelines are inefficient and process redundant data.
From a technical perspective, this model fundamentally misaligns with how modern data infrastructure actually works. Storage and compute resources scale sub-linearly with data volume, so why should your bill scale linearly with row counts?
What High-Performing Data Teams Do
They Benchmark Costs
Smart teams assess their current ETL spend before renewal. They ask:
- How much is spent on unchanged data?
- Which pipelines drive most of the cost?
- Would daily syncs suffice over hourly?
A financial services client found that 72% of their ETL spend came from just three data sources.
They Pilot Alternatives
Using tools like Matatika’s Mirror Mode, teams can run parallel tests. This allows them to:
- Validate savings
- Compare performance
- Ensure consistency pre-migration
This approach de-risks change and creates leverage during contract negotiations.
They Automate Workflows
Modern teams build pipelines that are:
- Self-healing
- Event-driven
- Alert-enabled
- Validation-equipped
This reduces manual intervention and increases reliability.
Column vs Row Thinking – Apply It to Your Pricing Too
Just as we’ve evolved beyond row-based storage for analytical databases, it’s time to evolve beyond row-based pricing for ETL.
We don’t build analytical databases on row storage anymore, so why do we still accept row-based billing for ETL?
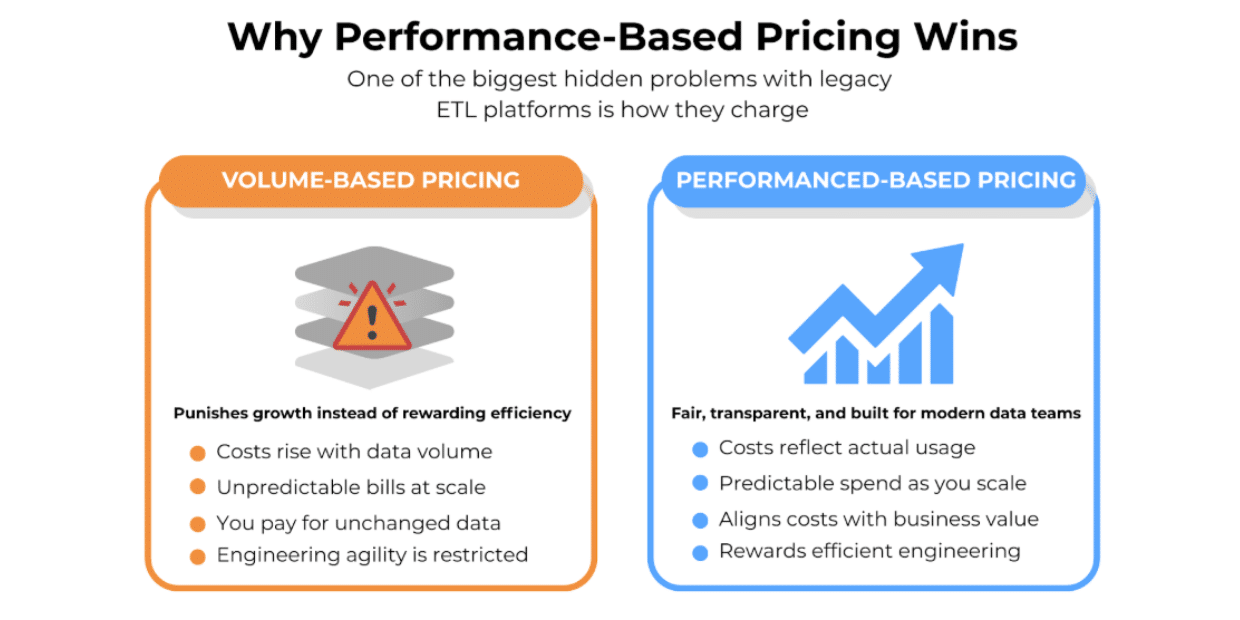
Performance-based pricing represents a fundamental shift in how ETL services are monetised:
| Row-Based Pricing (Legacy) | Performance-Based Pricing (Modern) |
| Charges per row processed | Charges for actual infrastructure used |
| Costs increase linearly with data volume | Costs align with actual compute resources |
| Penalises scale and growth | Scales efficiently with your business |
| Rewards vendor for inefficiency | Incentivises vendor to optimise performance |
For technical teams, this means your infrastructure costs finally align with actual resource consumption, CPU, memory, and IO operations, rather than an arbitrary metric that bears little relation to actual system load.
Most teams that switch to performance-based pricing save between 30-90% on their ETL costs by only paying for what they actually use.
Supporting Insight: The Real Cost of Row-Based Pricing
Recent industry research reveals the hidden toll of traditional ETL pricing models:
- Companies typically overpay by 30-70% on ETL due to row-based pricing inefficiencies
- 68% of data leaders report unexpected ETL cost increases in the past year
- Teams with performance-based pricing spend 62% less time justifying data costs to finance
One online media platform we worked with was struggling with both cost and performance issues. Their data delivery was too slow, and their ETL costs were growing unsustainably.
By implementing a performance-based pricing model with optimised incremental processing, they achieved:
- 3× faster data delivery – Updates every 15 minutes instead of 45-60 minutes
- 30% reduction in total costs – Even while processing more data
- Significant operational improvements including proper staging, data quality reports, and comprehensive monitoring
As their Data Team put it: “The reliability, speed, and cost savings have been remarkable, and the support is brilliant.”
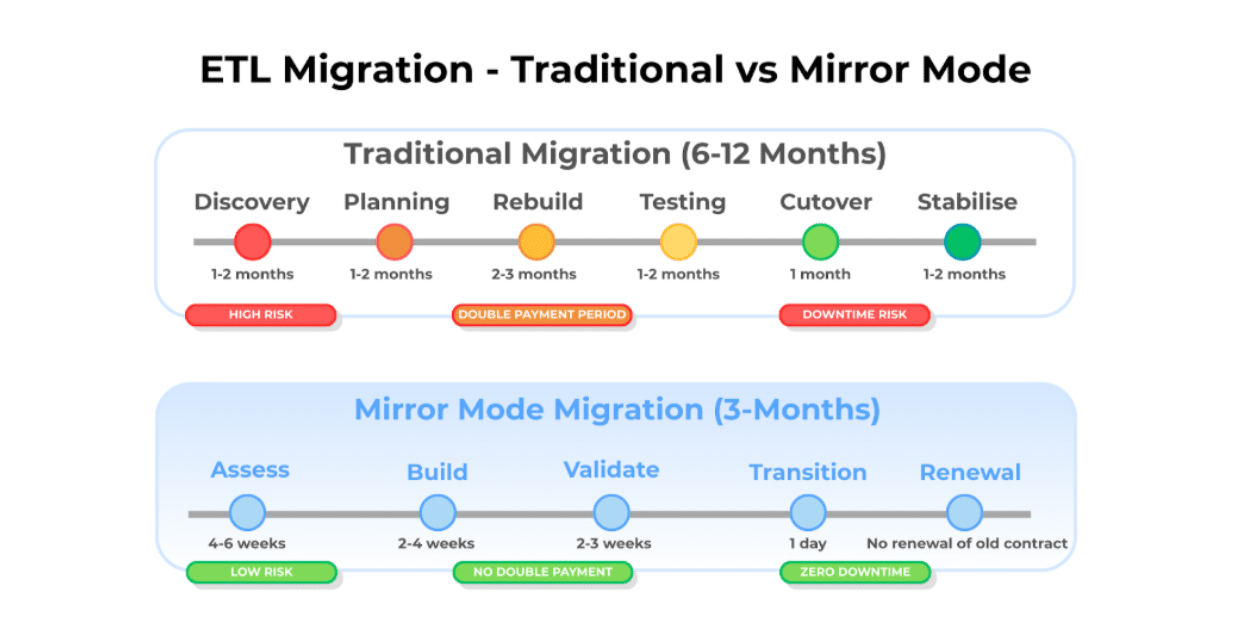
The Migration Challenge and Mirror Mode Solution
Most teams fear ETL migration because traditional approaches force an impossible choice: either rebuild all pipelines from scratch while paying for two systems during transition (often taking 6-12 months), or stay trapped in an inefficient pricing model.
Matatika’s Mirror Mode offers a better path. This approach allows both systems to run concurrently, so teams can validate performance, compare outputs, and ensure data consistency before committing to any changes, all in about 3 months rather than 6-12 months. Mirror Mode eliminates the risk that typically makes ETL transformations stressful, providing proof before commitment without double payments or downtime risk.
Frequently Asked Questions
How does performance-based pricing differ from consumption-based pricing?
Consumption-based pricing ties costs to data volume metrics like rows processed. Performance-based pricing focuses on actual computing resources used—regardless of how many rows move through pipelines. For finance teams, this means predictable costs that grow with infrastructure needs, not arbitrary data volumes.
Don’t costs increase as data volumes grow under any pricing model?
Yes, but at much slower rates with performance-based pricing. These models scale sub-linearly with data volume because efficient incremental processing means you only pay for changes, not full datasets. Most organisations see their cost curve flatten significantly over time, even as data volumes continue to grow.
When is the optimal time to evaluate ETL pricing models?
Ideally, begin exploring alternatives 3-6 months before your renewal date. This provides sufficient time to understand options, evaluate potential savings, and approach negotiations from a position of strength. Waiting until the last minute often results in reluctant renewals and missed savings opportunities.
How can data teams minimise risk when considering ETL changes?
Mirror Mode’s parallel approach eliminates the traditional risks of migration. By running both systems concurrently, you can compare outputs, validate performance, and verify data consistency before making any changes. This provides concrete evidence with your actual workloads, making decisions based on facts rather than fears.
From Trapped to Transformed
It’s time to stop paying for ETL inefficiency. A column vs row approach shows us a better way.
Performance-based pricing enables:
- Predictable budgets
- Fair, scalable billing
- Real operational improvement
Book a strategy session today to benchmark your current setup and explore potential savings using column vs row metrics.
With Matatika’s performance-based pricing and Mirror Mode approach, you can:
- Escape the row-based pricing trap without disruption
- Pay only for the resources actually used
- Scale confidently without cost surprises
- Future-proof data infrastructure for tomorrow’s analytics needs
Book your Renewal Ready Strategy Session
Ready to explore how performance-based pricing might benefit your organisation? Schedule a complimentary consultation to evaluate your current ETL environment.
Our experts will help you benchmark current costs, identify potential inefficiencies, and quantify possible savings, providing the clear data points needed for informed decision-making.
#Blog #Columnstore #Data Infrastructure #ETL Pricing #Migration Strategy #Performance-Based Billing
Data Leaders Digest
Stay up to date with the latest news and insights for data leaders.