
Building Data Trust Through Effective ETL Staging Environments
Most data teams don’t implement proper ETL staging environments because they seem complex, expensive, and difficult to secure. They stay with risky production-only deployments because establishing a proper testing workflow feels overwhelming. But the real risk is in doing nothing, leaving your critical data pipelines vulnerable to untested changes and unexpected failures.
The Problem: ETL Testing Is Broken
Data-driven companies are redefining the roles and processes of analytics engineering. With more teams embracing modern ETL migration tools to create efficient data pipeline staging environments, new approaches to create reliable testing workflows are essential.
Yet many organisations struggle with implementing proper ETL staging environments because:
- Traditional staging environments are prohibitively expensive, most ETL vendors charge the same row-based rates for staging as production
- Setting up parallel environments is technically complex, requiring duplicate credentials, infrastructure, and maintenance
- Testing with realistic data introduces security risks, potentially exposing sensitive information
- Coordinating deployments across environments is error-prone, leading to configuration drift and failed migrations
These challenges leave many teams deploying changes directly to production, a practice that would be unthinkable in modern software development. The consequences are predictable: broken dashboards, missed insights, and eroded trust in data.
What Smart Data Teams Do Differently
Forward-thinking data teams are applying the “shift left” testing methodology to their ETL workflows. In software development, shift left ETL means pushing testing, quality checks, and validation earlier into the development process. For analytics engineering teams, this translates into catching pipeline bugs, schema mismatches, and modelling issues before they reach production.
They Use Dedicated ETL Staging Environments
On the Matatika platform, environments are structured using workspaces that encapsulate your ETL pipelines, data sources, dbt models, and configuration. Smart teams implement this separation:
- Separate Git branch (e.g., “staging”) that mirrors your production branch
- Distinct workspace with staging-specific credentials and configurations
- Dedicated database that mimics production without risking live data
This setup ensures that releases from staging to production are seamless, without touching production until fully validated. Think of it like upgrading a motorway without closing the road, complete with 99.9% uptime.
They Optimise for Cost-Efficiency
Running full ETL pipelines in staging environments can be wasteful and resource-intensive. With Matatika’s performance-based pricing, you can implement these optimisations:
- Run staging pipelines only when needed – not on the same schedule as production
- Use subsets of production data – filtered by time period or other sampling methods
- Simulate ingestion from production sources – without duplicating full data loads
Unlike row-based pricing models that charge for every processed row regardless of environment, Matatika’s performance-based pricing means you pay for the infrastructure you actually use. Nothing more. There are no arbitrary row counts or compute inflation from inefficient syncs, just transparent costs that align with actual usage.
They Use Mirror Mode for Safety
Matatika’s Mirror Mode allows teams to run new and existing ETL systems in parallel. This four-step process ensures safety throughout:
- ASSESS – We review your existing setup and identify opportunities for improvement
- BUILD – We mirror your data ecosystem in parallel, without disrupting operations
- VALIDATE – Both systems run with real workloads, allowing you to verify everything works
- TRANSITION – Once confident, we coordinate a clean cutover timed with your renewal
Mirror Mode works by creating an exact replica of your ETL processes in a separate workspace that runs alongside your existing system, using the same data sources but with its own optimised infrastructure. This allows you to validate performance and output accuracy before making any changes to production.
This approach eliminates the uncertainty that typically makes ETL transformations stressful and risky. As one data leader described it: “It’s like having a safety net under your safety net.”
Learn more about Mirror Mode and how it works
How to Implement Secure ETL Staging: The Data Source Question
A common challenge for ETL staging environments is choosing appropriate data sources. Here are the three viable approaches supported by Matatika:
| Approach | Description | Pros | Cons |
| Production Sources | Staging pulls live data from production apps | Realistic data, accurate modelling | Risk of sensitive data exposure |
| Development Sources | Early-stage apps feed data to staging | Enables model co-development | Often contains incomplete data |
| Hybrid | Development data for building, production copies for validation | Flexible, low risk | Adds operational complexity |
Cloning Production Data (Securely)
Instead of pulling directly from source systems, you can treat the production data warehouse as a staging source. This is a fast and convenient way to validate models using production-shaped data, without re-triggering ingestion or stressing source systems. There are two primary approaches to doing this securely:
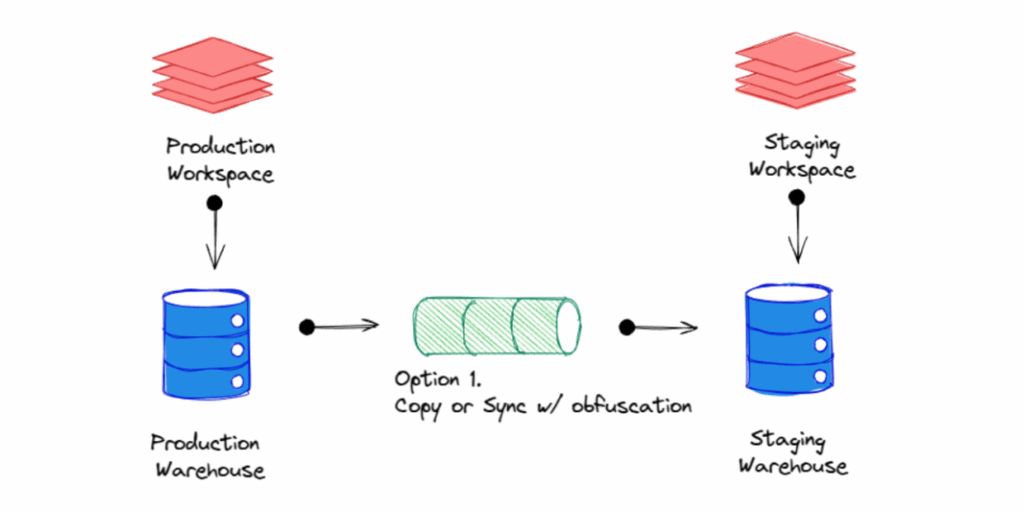
Option 1: Obfuscate Sensitive Fields During Copy
During the data cloning process, usually initiated from the production workspace, you can replace sensitive information such as names, emails, and phone numbers with fake or tokenised values. This lets you retain schema fidelity and data volume while avoiding privacy risks.
For example:
- Replace names with fake names (e.g., John Doe)
- Replace emails with dummy addresses (e.g., [email protected])
- Keep referential integrity intact (e.g., same fake email across joins)
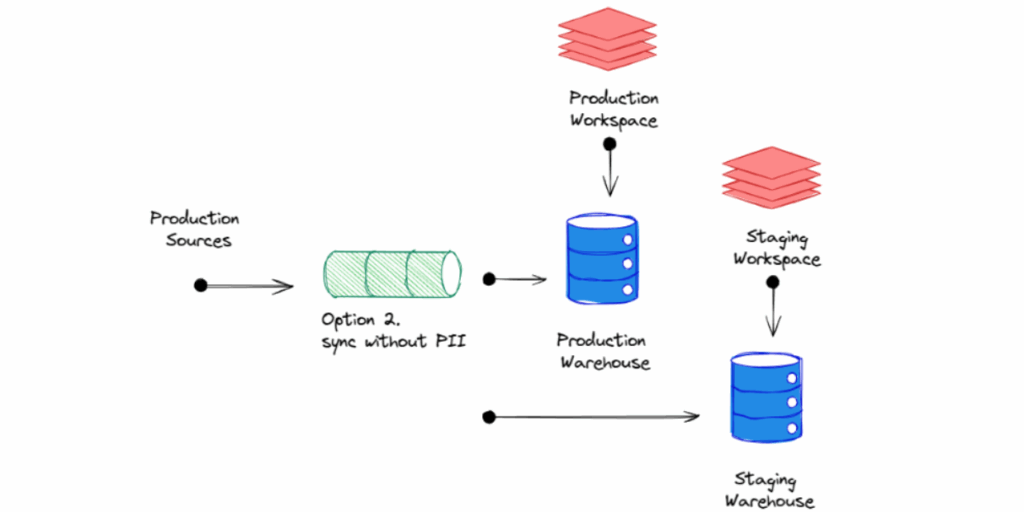
Option 2: Exclude Non-Essential PII Columns
Alternatively, you can omit columns containing PII entirely if they aren’t used in downstream models or analytics. This reduces the risk even further and keeps your staging datasets lean.
For example:
- Drop email, phone_number, or full_name fields if they’re not used for aggregations or joins
- Keep only the IDs and business-critical attributes needed for testing
Tip: You can maintain model compatibility by explicitly selecting only required columns in your dbt models or creating staging-specific views that exclude PII.
This setup has multiple benefits:
- Security: No real PII enters your staging workspace
- Performance: Smaller datasets improve test run times
- Simplicity: You don’t need to manage obfuscation logic for unused fields
And since this cloning process is initiated in the production workspace, staging doesn’t need direct credentials to upstream systems, keeping access and risk tightly controlled.
Supporting Insight: The Real Cost of Poor ETL Testing
The risks of skipping proper ETL staging environments extend beyond just technical issues. Recent industry research reveals:
- 72% of data teams experienced production pipeline failures that proper testing would have caught
- The average cost of a significant ETL failure was estimated at £38,000 in lost productivity
- Teams with proper staging environments detected 3.5x more issues before production deployment
These statistics highlight why proper ETL staging environments are not optional, they’re essential for data reliability.
One data leader put it plainly: “We spent three years trying to save money by skipping staging environments. We ended up spending ten times what we saved dealing with production issues.”
Key Takeaways
- A strong staging architecture is essential for reliable ETL tool development and data ingestion pipelines.
- Use Matatika workspaces to separate environments cleanly via Git branches, configs, and credentials. See our example
- Optimise staging for cost and performance while ensuring data quality and security.
- Consider cloning from production for model testing while obfuscating sensitive data.
- Embrace the “shift left” mindset, test early, deploy confidently.
Frequently Asked Questions
How does Matatika’s approach to ETL staging differ from traditional tools?
Traditional ETL tools typically require duplicate infrastructure and charge the same row-based rates for staging as production. Matatika’s workspace architecture provides clean environment separation with performance-based pricing that reflects actual usage, not arbitrary row counts. This makes staging environments both technically simpler and financially feasible.
Do I need to duplicate my entire ETL pipeline for staging?
No. With Matatika, you can selectively clone parts of your pipeline that require validation while simulating others. Our workspace architecture allows you to define which components need real testing versus which can be mocked or simplified, saving both time and resources.
How do I handle database credentials across environments?
Matatika workspaces include integrated credential management that separates staging from production access. This means your staging environment can use limited-permission database roles and restricted access patterns without complicated credential juggling or risky permission sharing.
Can I test data pipelines without exposing sensitive information?
Yes. Matatika supports both data obfuscation and column exclusion approaches. Our platform makes it easy to implement automatic PII removal or replacement during the staging process, ensuring that sensitive information never leaves your production environment.
How much does implementing a proper staging environment cost?
With Matatika’s performance-based pricing, staging environments typically cost 60-70% less than production since they process less data and run less frequently. Unlike row-based pricing models that charge the same regardless of actual usage, you’ll only pay for the resources you consume.
From Risky Deployments to Confident ETL Testing
The shift from risky production-only deployments to secure, efficient ETL staging doesn’t have to be complex or expensive. With Matatika, you can:
- Create isolated testing environments with minimal overhead
- Test with production-like data without security risks
- Pay only for the resources you actually use
- Deploy to production with complete confidence
Book your 45-minute ETL renewal planning session
We’ll review your setup, compare cost and performance, and give you a migration-ready roadmap for implementing proper ETL staging environments.
#Blog #analytics engineering #data pipeline testing #data workflow security #ETL staging environment #Matatika
Data Leaders Digest
Stay up to date with the latest news and insights for data leaders.